서론
"객체 지향 프로그래밍(OOP)은 만능일까?" 학교나 학원에서 C++을 배우면 캡슐화, 상속, 다형성과 모든 것을 객체(Object)로 모델링하는 법을 우선적으로 배운다. 일반적인 상황에서는 OOP의 철학대로 설계를 하는것이 바람직하지만 최적화가 중요한 프로젝트에서는 OOP가 CPU 캐시를 괴롭히는 주범이라며 이를 피하려 한다. 오늘은 성능 최적화의 핵심 패러다임인 데이터 지향 프로그래밍(Data-Oriented Programming, DOP)에 대해 알아보자.
데이터 지향 프로그래밍(DOP)이란?
DOP는 데이터가 메모리에 어떻게 배치되는가를 최우선으로 고려하는 프로그래밍 기법이다.
OOP가 현실 세계를 코드로 모델링하는 것에 집중한다면, DOP는 하드웨어(CPU, 캐시, 메모리)가 데이터를 효율적으로 처리할 수 있는 형태로 데이터를 조직하는 것에 집중한다.
즉, 데이터의 레이아웃(Layout)을 최적화하여 CPU 캐시 히트율(Cache Hit Rate)을 높이고, 불필요한 메모리 접근을 줄이는 것이 핵심 목표다. (캐시 히트에 관련한 내용은 이전 게시글에 다루었다)

OOP의 문제점: 캐시 미스(Cache Miss)
일반적인 OOP 방식의 게임 오브젝트 배열을 보자. 이를 AoS (Array of Structures) 구조라고 한다.
class Monster {
public:
Vector3 position; // 12 bytes
int hp; // 4 bytes
Mesh* mesh; // 8 bytes (64bit)
AI* ai; // 8 bytes
// ... 수많은 데이터와 포인터들 ...
virtual void Update() { ... }
};
std::vector<Monster*> monsters;몬스터 1000마리를 Update 돌릴 때 어떤 일이 벌어질까?
- monsters[i]는 포인터다. 실제 Monster 객체는 힙(Heap) 메모리 여기저기에 흩어져 있다(메모리 파편화).
- position을 읽으려 할 때마다 캐시 미스(Cache Miss)가 발생한다. CPU는 램(RAM)에서 데이터를 가져오느라 수백 사이클(Latency)을 낭비한다.
- 물리 연산만 하려는데 필요 없는 데이터(mesh, ai, 가상 함수 테이블 포인터 등)까지 캐시 라인(Cache Line, 보통 64바이트)에 딸려 들어와서 캐시 오염(Cache Pollution)을 유발한다.
결과적으로 CPU는 데이터를 기다리느라 대부분의 시간을 Stall(대기) 상태로 보내게 된다.
DOP의 해결책: SoA (Structure of Arrays)
DOP는 이를 해결하기 위해 데이터를 종류별로 쪼개서 연속된 메모리에 배치한다. 이를 SoA(Structure of Arrays) 구조라고 한다.
struct MonsterData {
std::vector<Vector3> positions; // 위치 데이터만 모음
std::vector<int> hps; // HP 데이터만 모음
std::vector<Mesh*> meshes; // 메쉬 포인터만 모음
};
void UpdatePhysics(MonsterData& data, int count) {
for (int i = 0; i < count; ++i) {
// 물리 연산 수행 (positions만 접근)
data.positions[i] += velocity * dt;
}
}이렇게 데이터를 분리하면 다음과 같은 이점이 생긴다.
- 공간 지역성(Spatial Locality): positions 배열은 메모리에 연속적으로 존재한다. 한 번 캐시에 로드되면 인접한 데이터(다음 몬스터의 위치)들이 함께 캐시 라인에 들어오므로 캐시 히트율이 급상승한다.
- 필요한 데이터만 로드: 물리 연산을 할 때는 positions만 읽으면 된다. mesh나 ai 데이터는 캐시에 들어오지 않아 캐시 효율(Bandwidth)이 좋아진다.
- SIMD(Single Instruction Multiple Data) 최적화: 데이터가 정렬되어 있고 타입이 동일하므로, 벡터 연산(SSE, AVX 등)을 적용하기가 훨씬 수월해진다. 컴파일러가 자동 벡터화(Auto-Vectorization)를 하기도 좋다.
AoS vs SoA 비교
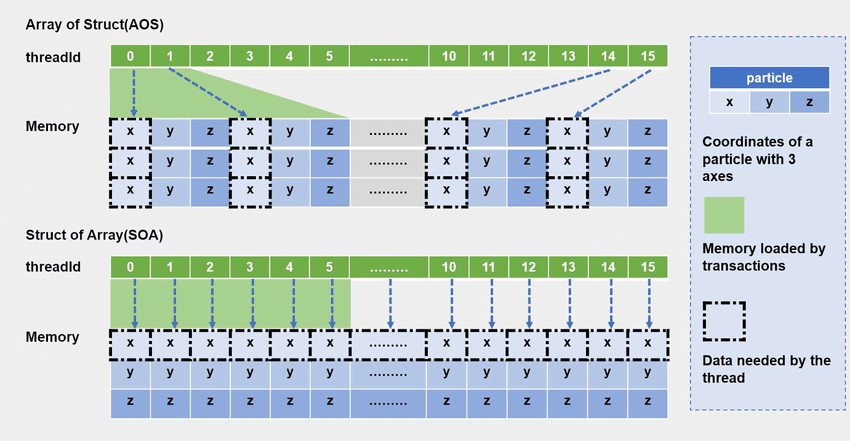
| 구분 | AoS (Array of Structures) | SoA (Structure of Arrays) |
|---|---|---|
| 구조 | struct { x, y, z } arr[N] |
struct { x[N], y[N], z[N] } |
| 패러다임 | 객체 지향 (OOP) | 데이터 지향 (DOP) |
| 메모리 배치 | 객체 단위로 연속 (필드 섞임) | 필드(속성) 단위로 연속 |
| 캐시 효율 | 낮음 (불필요한 데이터 로드) | 매우 높음 (필요한 데이터만 로드) |
| SIMD 활용 | 어려움 | 용이함 |
결론

그렇담 최적화는 언제나 옳으니 당장 기존 AoS 방식을 버리고 SoA로 변경해야한다는 것은 또 아니다. 코드의 유지보수성과 가독성, 추상화를 생각하면 AoS 설계가 얻는 이점이 명확하다. 하지만 극한의 성능이 필요한 게임 엔진 코어, 물리 엔진, 대규모 유닛 처리(RTS, 군중 시뮬레이션)등 특수한 상황에 SoA를 고려해야한다는 것이다.
Unity의 DOTS (Data-Oriented Technology Stack)나 Unreal의 Mass Entity 시스템도 결국 이 DOP 철학을 바탕으로 만들어진 것이다. 게임 개발자라면 하드웨어가 데이터를 어떻게 읽는지 이해하고, 상황에 맞는 패러다임을 선택할 수 있어야 한다.
'Computer Science' 카테고리의 다른 글
| [CS] 운영체제가 사용하는 메모리 영역 (0) | 2025.07.14 |
|---|---|
| [CS] 아스키코드와 유니코드, EUC-KR과 UTF-8 차이 (0) | 2025.05.14 |
| [CS] 프로세스(Process)와 스레드(Thread) (0) | 2025.04.30 |
| [CS] 캐시 메모리(Cache Memory) (0) | 2025.04.30 |