4.4 Thread Configuration
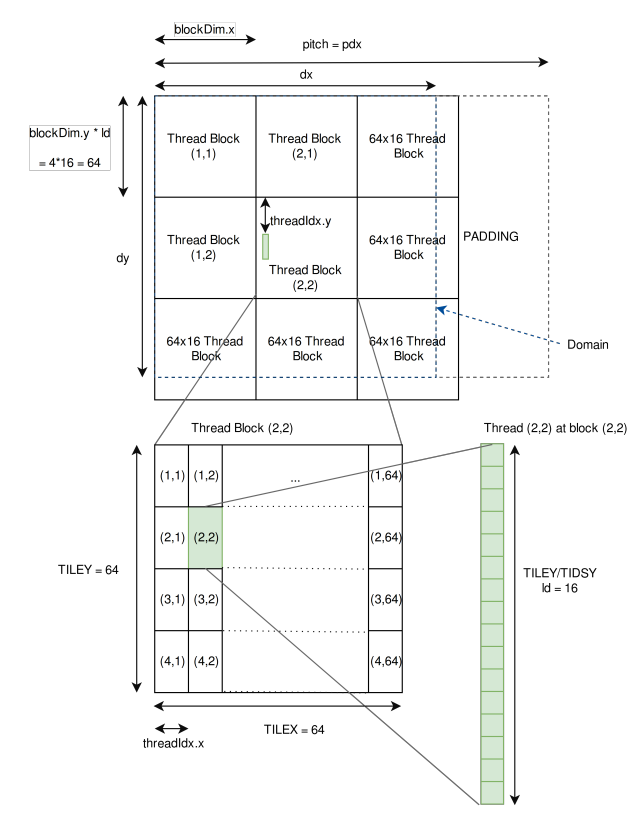
First, we choose a warp-size multiple for the block horizontal size: 32 · 2 = 64. Then we have to choose a block vertical size. Because the typical maximum threads per block is 1024, we cannot choose 64 for the vertical dimensions, as we would have 64 · 64 = 4096 threads! For this reason we choose a 64x4 block size (256 threads per block). We divide the domain size in 64x64 square tiles and assign each tile to a block. This means the four vertical threads will have to process 16 grid vectors each one in order to process the entire square: 64 · 4 · 16 = 64 · 64. This domain division is shown in fig 5.
먼저 블록 수평 크기에 대한 워프 크기의 배수를 32 · 2 = 64 와 같이 선택한다. 그 다음 블록 세로 크기를 선택해야 하는데, 블록당 일반적인 최대 스레드 수는 1024개이므로 수직 치수는 64개, 64개 = 4096개이므로 64개를 선택할 수 없다! 따라서 64x4 블록 크기(블록당 256 스레드)를 선택한다.
도메인 크기를 64x64 정사각형 타일로 나누고 각 타일을 블록에 할당한다. 이것은 네 개의 수직 스레드가 전체 정사각형을 처리하기 위해 각각 16개의 그리드 벡터를 처리해야 한다는 것을 의미한다: 64 · 4 · 16 = 64 · 64. 이 도메인 분할은 그림 5에 나와 있다.
Once we know how the thread configuration works, we can create a template which will work for launching all simulation-step kernels. Pay close attention to the template commentary as it adds further explanations.
스레드 구성이 어떻게 작동하는지 알게 되면 모든 시뮬레이션 단계에 대한 커널을 시작하는 데 사용할 템플릿을 생성할 수 있다. 템플릿에는 추가 설명을 덧붙였으니 주의 깊게 보아야 한다.
void simulationStepKernel_launcher() {
// 도메인이 64x64 타일과 완벽하게 맞지 않는 경우에도
// 모든 스레드가 활용되지 않는 타일을 추가한다.
// 존재하지 않는 도메인 좌표에 대한
// 메모리 위치에 접근하지 않도록 주의해야 한다.
dim2 grid((dx/64)+(!(dx%64)?0:1), (dy/64)+(!(dy%64)?0:1));
dim2 tids(64, 4);
// cudaMallocPitch를 사용한 후에 얻은 피치 값을 커널에 전달해야 한다.
simulationStepKernel_k<<<grid, tids>>>simulationStepKernel_k(tPitch,...);
}
__global__ void simulationStepKernel_k(size_t pitch, ...) {
// 해당 스레드가 작동해야 하는 첫 번째 그리드 좌표 위치(gtidx, gtidy)를 계산한다.
// 그림 5을 기반으로 한다.
int gtidx = blockIdx.x * blockDim.x + threadIdx.x;
int gtidy = blockIdx.y * (16 * blockDim.y) + threadIdx.y * 16;
if (gtidx < dx) {
// 이 if문을 통해 존재하지 않는 도메인 좌표에 대한
// 존재하지 않는 메모리 위치에 액세스를 방지한다.
// 이 좌표는 첫 번째 좌표에서 +y축 방향으로 이동하는 것을 볼 수 있다.
for (int p = 0; p < 16; p++) {
int gtdiyy = gtidy + p;
// 다시 말하지만 존재하지 않는 좌표에 액세스하지 않도록 한다.
if (gtdiyy < dy) {
// 피치를 고려한 인덱스 피치 값이
// 바이트 단위이기 때문에 바이트 단위로 계산해야 한다.
cData* f = (cData *)((char *)v + gtdiyy * pitch) + gtidx;
// f 포인터를 사용하여 쓰기/읽기 를 한다.
// 마지막으로 vxfield와 vyfield에 대한 메모리 인덱스를 계산한다.
// 이 인덱스는 vxfield와 vyfield 모두 적용된다.
int fj = gtdiyy*pitch + gtidx;
// vxfield[fj]; vyfield[fj];
// 여기에 시뮬레이션 단계별 코드를 삽입하면 된다.
}
}
}
}With the template already made, we only need to insert each simulation-step specific code after the f index is calculated. This is straight-forward knowing the CPU implementation code, few minor changes are required.
템플릿이 이미 만들어졌으므로 f 인덱스가 계산된 후에 각 시뮬레이션 단계별 코드를 삽입하기만 하면 된다. 이것은 CPU 구현 코드를 알기 쉽고, 약간의 변경이 필요하다.
4.4.1 External Forces
For the addForces method, as we only have to compute a small tile of 9x9 (when radius is 4), we only need to launch the kernel with a single 9x9 block thread.
addForces 메서드의 경우 9x9의 작은 타일(반경이 4일 때)만 계산하면 되기 때문에 9x9 블록 스레드를 하나만 사용하여 커널을 시작하면 된다.
#define FR 4 // Force update radius
dim3 tids(2*FR+1, 2*FR+1);
addForces_k<<<1, tids>>>(...);'GPU Programming > CUDA fluidsGL' 카테고리의 다른 글
| Real-Time GPU Fluid Dynamics 번역 (2) (1) | 2022.07.20 |
|---|---|
| Real-Time GPU Fluid Dynamics 번역 (1) (0) | 2022.07.20 |
| 0. Introduction (0) | 2022.07.19 |